天之道,其犹张弓欤?高者抑之,下者举之en馀者损之,不足者补之,天之道损有馀而补不足。人之道则不然,损不足以奉有馀。孰能有馀以奉天下,唯有道者。(道法自然)自然规律,就犹如射箭一样,弓位高了就往下压一压(高者抑之),弓位低了就往上抬一抬(下者举之)。用多余去补不足。人之道(规律),则不是这样。它是损不足去奉多余。什么样的人才能用有余去奉天下呢?唯有有道者。因此圣人为而恃,功成而不处,不会去想在众人面前立贤名,以均天下。搜索所遵循就是这样的一个规律。
据统计表明,近似重复网页的数量占总网页数量的比例高达全部页面的29%,而完全相同的页面大约占全部页面的22%,即互联网页面中有相当大的比例的内容是完全相同或者大体相近的重复网页有多种类型,这些重复网页有的是没有一点儿改动的副本,有的在内容上稍做修改,比如同一文章的不同版本,一个新一点,一个老一点,有的则仅仅是网页的格式不同(如HTML、Postscript)。内容重复可以归结为以下4种类型。
· 类型一:如果两篇文档内容和布局格式上毫无差别,则这种重复可以叫做完全重复页面。
· 类型二:如果两篇文档内容相同,但是布局格式不同,则叫做内容重复页面。
· 类型三:如果两篇文档有部分重要的内容相同,并且布局格式相同,则称为布局重复页面。
· 类型四:如果两篇文档有部分重要的内容相同,但是布局格式不同,则称为部分重复页面。
所谓近似重复网页发现,就是通过技术手段快速全面发现这些重复信息的手段,如何快速准确地发现这些内容上相似的网页已经成为提高搜索引擎服务质量的关键技术之一。
发现完全相同或者近似重复网页对于搜索引擎有很多好处。
1. 首先,如果我们能够找出这些重复网页并从数据库中去掉,就能够节省一部分存储空间,进而可以利用这部分空间存放更多的有效网页内容,同时也提高了搜索 引擎的搜索质量和用户体验。
2. 其次,如果我们能够通过对以往收集信息的分析,预先发现重复网页,在今后的 网页收集过程中就可以避开这些网页,从而提高网页的收集速度。有研究表明重 复网页随着时间不发生太大变化,所以这种从重复页面集合中选择部分页面进行 索引是有效的。
3. 另外,如果某个网页的镜像度较高,往往是其内容比较受欢迎的一种间接体现也就预示着该网页相对重要,在收集网页时应赋予它较高的优先级,而当搜索引擎系统在响应用户的检索请求并对输出结果排序时,应该赋予它较高的权值。
4. 从另外一个角度看,如果用户点击了一个死链接,那么可以将用户引导到一个内容相同页面,这样可以有效地增加用户的检索体验。因而近似重复网页的及时发现有利于改善搜索引擎系统的服务质量。
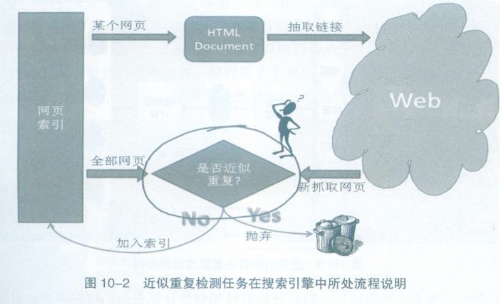
实际工作的搜索引擎往往是在爬虫阶段进行近似重复检测的,下图给出了近似重复检测任务在搜索引擎中所处流程的说明。当爬虫新抓取到网页时,需要和已经建立到索引内的网页进行重复判断,如果判断是近似重复网页,则直接将其抛弃,如果发现是全新的内容,则将其加入网页索引中。