作为SEOer,我们使用的各种各样的工具,以收集各式各样的技术问题,网站分析,抓取诊断,百度站长工具等。所有这些工具是有用的,但都无法比拟在网站日志数据分析搜索引擎蜘蛛抓取,就像Googlebot到爬取您的网站并您的网站上留下了一个真实的记录。这是网络服务器日志。日志是一个强大的源数据经常没有得到充分利用,但有助于保持您的网站的搜索引擎抓取检查的完整性。
服务器日志是由一个特定的服务器进行详细记录了每一个动作。在一个Web服务器的情况下,你可以得到很多有用的信息。如何检索和分析日志文件,并根据您的服务器的响应代码(404,302,500等)的识别问题。我将它分解成2个部分,每个部分突出不同的问题,可以发现在您的Web服务器日志
一、获取日志文件
搜索引擎抓取网站信息必会在服务器上留下信息,这个信息就在网站日志文件里。我们通过日志可以了解搜索引擎的访问情况,一般通过主机服务商开通日志功能,再通过FTP访问网站的根目录,在根目录下可以看到一个log或者weblog文件夹,这里面就是日志文件,我们把这个日志文件下载下来,用记事本(或浏览器)打开就可以看到网站日志的内容。那么到底这个日志里面隐藏了什么玄机呢?其实日志文件就像飞机上的黑匣子。我们可以通过这个日志了解很多信息,那么到底这个日志给我们传递了什么内容呢?下面先做一个简单的说明。
日期:这将让你一天搜索引擎抓取速度的发展趋势进行分析。
被爬取文件:这将告诉你哪些被抓取的目录和文件,并在某些路段或类型的内容可以帮助查明问题。
状态码:(只列出常见到并能直接反正网站问题的状态码)
200状态码:请求已成功,请求所希望的响应头或数据体将随此响应返回。
302状态码:请求的资源现在临时从不同的URI响应请求。
404状态码:请求失败,请求所希望得到的资源未被在服务器上发现。
500状态码:服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。
- - 提供了哪些网页被爬虫运行到并反应出什么样的问题。
从哪里来:虽然这不一定是有用的分析搜索机器人,它是非常有价值的,其他的流量分析。
哪种爬虫:这个会告诉你哪个搜索引擎爬虫在你的网页上运行的。
二、解析网站日志文件
现在你需要一个日志分析工具,因为如果你的网站有几M或几十M甚至百M以上的日志数据时,你不可能一条条去看。再说,就算日志数据不多,一条条看也是不科学的。这里用光年seo日志分析工具为大家做个例子。
1.导入文件到您解析软件。
2.分析网站日志及时发现出现的问题
搜索引擎抓取您的网站有最快的方式是看在正在服务的服务器响应代码。404(找不到页面)可能意味着抓取那珍贵的资源被浪费了;302重定向请求的资源现在临时从不同的URI响应请求;500是服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理,可以分析出服务器出现的问题。虽然网站管理工具提供了一些信息,这样的错误,会给你的网站造成一个非常大的影响。
分析的第一步是从您的日志数据,通过光年seo日志分析工具以产生一个数据表。在最基本的层面上,让我们看看哪些搜索引擎的爬虫在爬行这个网站:
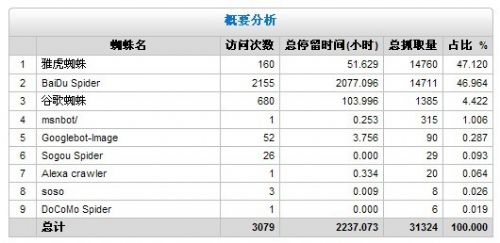
通过报表我们想几个问题:
a.雅虎蜘蛛总抓取量占了全部的47.12%;那么我从流量统计器看到。没有一个流量是从雅虎搜索引擎过来的。那么这个蜘蛛可不可以禁止他再来访问呢?
b.百度蜘蛛(BaiDu Spider )的访问次数、停留的时间、总抓取量反应了什么呢?
c.其它搜索引擎的蜘蛛的访问次数、停留的时间、总抓取量那么少的原因是什么呢?有没有改善的方法呢?
接下来,让我们来看看在蜘蛛状态码分析,我们最关心的问题。
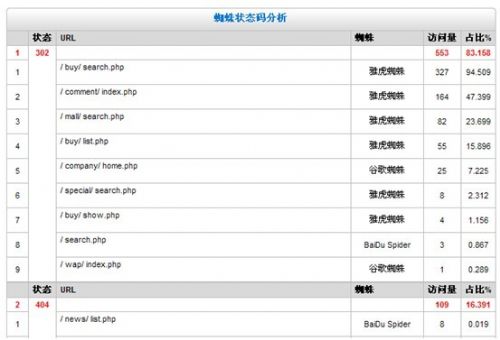
这是只显示这个日志有问题的蜘蛛状态码,而已正常200将不被分析。我们将要细看这个表格。总体而言,好到坏的比例看起来很健康,但有一些个别的问题让我们尝试弄清楚这是怎么回事。
302出现的问题数量是可以接受的,但是不代表可以放着不去处理,我们应该有更好的方法来处理这些问题,也许用一个robots.txt指令应排除这些页面被抓取。
404的出现达到109个。在几万的抓取量来说。网站的这个数据也算是可以的。但是也需要解决,找出潜在的问题是隔离404目录或者使用rel =”nofollow”注释这些404链接。当然404的页面也必须要有。
结语
百度网站管理为您提供抓取错误的信息,但在许多情况下,它们限制了数据。作为SEO的,我们应该利用一切可用的数据,毕竟只有一个数据源,你可以真正依靠自己的源。日志不撒谎!
