【前言】
应朋友们的要求,我还是写一篇关于服务器日志法进行网站分析的原理以及它的优缺点是什么。请朋友们注意,网站服务器日志法并不容易进行,初学者,以及在绝大多数情况下,进行以用户行为分析为核心的网站分析,用不到服务器日志法。不过,作为网站分析历史不可分割的一部分以及重要的基础篇章,服务器日志法仍然值得一书。下面的这篇文章也是我要撰写的书中截取的内容(我要快马加鞭快快写了,已经辜负了太多朋友的重托,抱歉抱歉!)。
【正文】
网站分析收集数据的方式其实有五、六种之多,我们最常见的有三种,分别是:服务器日志(Server Log)、页面标记(Page Tag)和客户端监测软件收集(Client End/Desktop)。我的CWA博客(http://www.chinawebanalytics.cn)中主要讲解的都是页面标记法,今天则跟大家讲解一下服务器日志方法的原理及优缺点。
1. 服务器日志是什么
真正意义上的网站分析是从服务器日志开始的,而且直到今天,分析服务器(也称为server log file,或简称log file)日志仍然是网站分析的重要方法。
这里的服务器指的是网站服务器(Web Server),而服务器日志跟飞机的黑匣子一样,是用来记录网站服务器的运行信息的,或者简单说,是用来记录服务器中的什么页面在什么时候被谁访问了。例如,如果你访问一次我的网站:http://www.chinawebanalytics.cn,那么一般情况下,网站服务器的日志就会记录在某时某刻来自某个IP的访问者索引了网页“/index.php”。当然,网站服务器日志还会记录其他许多内容,这些内容能够帮助我们分析网站的流量和访问者在网站上的行为。
下面这个图说明了网站日志是如何产生的。当用户访问一个网站的时候,事实上是访问这个网站的某一个具体的页面,我们假设这个页面叫Page 1。这时,我们的这个访问行为会请求服务器中Page 1的实际的文件,随之把这个文件下载到浏览器上。由于请求和下载行为都会引起服务器的响应和相应的行动,因此就有必要记录下服务器的这些行动。
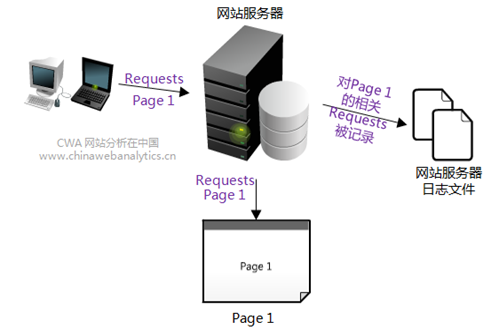
你会问,为什么需要记录服务器的行动呢?原因很简单,因为我们不想让这个服务器变成“哈尔9000”(哈尔9000是库布里克《2001太空奥德赛》里面有了自我意识的电脑,它直接威胁到了电影中的宇航员)啊!这当然只是开玩笑,不过目的并无差别,就是能够通过服务器日志,对服务器的运行历史进行记录,这样当有任何异常情况发生的时候,我们都能够通过日志探寻问题发生的原因——跟记录飞机运行状态的黑匣子的作用十分类似。
原理看起来并不复杂,不过log file实际上并不简单。为了让log file具有可读性,log file并不可以按照各个网站所有者的喜好随意记录的,而是有自己的规范。W3C组织定义了server log file的通用格式(如果你有兴趣,可以在这里看看这些格式都是如何定义的:http://www.w3.org/Daemon/User/Config/Logging.html#common_logfile_format),而其他一些组织或者个人又根据自己的需要额外扩展了这个格式,使log file能够比较全面地记录网站服务器进行的各种活动。
一条标准的web server log记录通常包含如下信息:
l 远程主机(Remote Host)的IP地址/名字
 l 登录名(Log Name)
l 登录名(Log Name)
l 登录全名(Full Name)
l 请求发生的日期(Date)
l 请求发生的时间(Time)
l 和标准格林威治时间的差值(GMT Offset)
l 请求的方法(Request Method)
l 请求的文件的地址(File)
l 请求遵守的协议(Protocol)
l 请求的状态(Status)
l 被请求文档的长度(Length)
下面是一条标准的log file记录:
202.71.113.38 – - [03/Jan/2010:01:56:12 +0800] “GET /Chinawebanalytics/Sidney.htm HTTP/1.0” 200 5122
从左到右,202.71.113.38就是远程主机的IP;而登录名和登录全名指的是发起这个请求的用户的名字,这个一般大家当然是不想要透露的了,所以远程主机会禁止给出这两个信息,log file当然就记录不下来了,用两个短中划线代替。然后,03/Jan/2010是请求发生的日期,01:56:12则是时间,之后的+0800是指比格林威治时间要晚8个小时,就是我们北京时间了。再之后的GET是请求的方法,另一种方法是POST,可以简单理解为GET就是索取,POST就是提交。接着:/Chinawebanalytics/Sidney.htm是被请求文件的地址,可以是绝对地址也可以是相对地址。HTTP/1.0是请求所遵守的协议,这里的协议是HTTP 1.0。整个记录的结尾是两个数字,其中200表示一种请求的状态,意思是请求一切正常。有时候这个数字会显示为404,相信大家一看到这个数字就头痛,它表示请求的文件无法找到(file not found);又有时候,这个数字会显示为301,表示页面被重新定向到了别的地址。最后的一个数字5593,表示所请求的文档的长度为5122 bytes。
通用格式其实很简单,但是里面的这11类记录往往不足够帮助我们进行更深入的分析,因此其他的一些记录被加入进来,其中最重要的一些是:
l 请求来源(Referrer):指连接到被请求资源的网站的URL。如果请求时通过点击一个链接时发生,那么这个项目就会被记录;
l 客户端(User Agent):记录用户的浏览器或者发出请求的程序的相关信息;
l 所需时间(Time Taken):从请求的发出到请求的资源全部传输完毕所需花费的时间;
l Cookie。
看起来,网站服务器日志所记录的内容是很有限的,比起我们动辄上万行的编程实在是九牛一毛。但是,千万别认为网站服务器日志文件会很小,对于一些大网站,每分每秒都有很多访问者对网站服务器进行请求,所以日志文件会积少成多,成为巨型的数据文件。有时候,一个小时的记录就能超过数G。什么,你网站的服务器日志一个月才1M?要加油啊,没有人气的网站可没有生命力。
讲到这儿,该说说历史了。网站分析就是从网站服务器日志开始的,或者更准确的说,网站服务器日志自诞生之日起,就是为网站分析所用的。最早,人们可是把所有的记录都拿出来,然后导入到数据软件中去进行分析,辛苦程度自不用说;但这个痛苦的阶段不会持续太久,哪儿有痛苦,哪儿就有生意,所以网站日志分析软件就出现了,解决了很大的问题,以至于大小互联网服务提供商(ISP)们都为租用他们空间的用户提供一款免费的网站日志分析软件。尽管如此,分析网站日志一直都是一个相当不容易的事情,所以,人们不得不寻找一些更便利的方法,这样便发明了网站分析的新的数据获取方法,这是后话了。
如果你问我什么情况下选择用网站服务器日志来进行网站分析,我建议你如非必须,那么还是寻找一些更容易的方法能够事半功倍。看看后面的内容,你就能知道我为什么这么说。
2. 用网站服务器日志进行网站分析的优点
尽管是个技术活,但是利用网站服务器日志进行网站分析还是有不少好处的。
1. 网站服务器的日志是被你完全掌控的数据。
所谓放在自己手心最放心,这些日志在你的服务器中,如果不是黑客入侵,数据不可能被你不希望的人获取。而且,只要你不删除,它们永远都在那里,在任何时候你都可以回溯历史数据,无论这些数据有多么久远。有朝一日,你的网站大获成功,这些日志也是一份奋斗历史的见证。
2. 能够记录机器人/自动程序对网站的访问。
其次,前面讲过,网站服务器的日志是记录网站服务器行为的,因此任何服务器响应的请求都会被记录下来。这些响应可能是应答用户发出的请求,也完全可能是应答一些互联网上自动程序发出的请求。最常见的一种互联网上的自动程序是搜索引擎的机器人,例如Google的Googlebot,这意味着网站服务器日志能够用来分析搜索引擎的访问,并帮助我们优化搜索引擎对网站的访问。讲到这里,请大家注意,并不是每一种网站分析方法都能做到这一点,我们最常用的为网站页面加入标签的方法是不能获取搜索引擎流量的。
3. 终端无关
网站服务器的日志能够记录网站服务器全部响应行为的特点还延伸出另外一个优点,那就是无论是何种终端访问服务器,都能把相关数据记录下来。现在,能够访问网站的终端越来越多了,我无聊的时候也试着用Sony的PSP上网,用手机的GPRS也能轻松的浏览网页,这些形形色色的终端的访问,服务器日志都会忠实的记录,但页面加入标签的方法就可能完全行不通。
4. 能够探知文件是否完全下载
日志方法的另一个好处是能够记录文件下载的情况。如果你在网上下载一个MP3音乐,你在发出这个响应的时候,日志会记录一个状态;你在下载完全的时候,日志照样会记录一个状态;如果你没有下载完全,日志还是会记录下来。这个,我想对那些提供下载服务的网站很有用。
5. 数据获取不依赖于第三方
通过日志获取数据本身不需要额外的第三方的帮助。只要你的服务器在运转,日志就会源源不断的被创建、保存。不过,请注意,这里我所指的是数据的获取不需要额外的支持,但是数据的分析一般而言,还是需要第三方的帮助的。直接去用肉眼读日志文件中的数据进行分析是不可想象的。
6. 不怕防火墙
最后,日志方法不惧怕防火墙或客户端安全软件的屏蔽,因为数据都是从服务器端获取的。
看起来似乎不错,不过凡事有利有弊,日志方法也肯定有它不能克服的不足。
3. 用网站服务器日志方法进行网站分析的缺点
日志方法能够起到作用的前提是服务器要响应来自客户端的请求,如果客户端的请求不通过服务器就得到了响应(这其实是经常发生的),那么服务器日志法就无能为力了。
1. 害怕网页缓存(Cache)
为了提高网站页面的载入速度,人们发明了网页缓存(Cache)。在台湾,Cache被翻译作“快取”,似乎兼备了音义。
网页缓存的原理很容易理解,但却是个了不起的发明。在缓存出现之前,人们访问网站每次都需要把网页从网站的服务器传输到客户端的浏览器中,这个速度当然会有点儿慢,尤其是网络条件不好的时候。于是善动脑筋的人们发现,每次访问的网站其实有很多内容是没有更新的,如果能够把那些不经常更新的部分放在自己的电脑里面,每次打开网页的时候,首先搜索自己电脑里面已经有的内容,然后再去服务器去寻找那些被更新了的部分,这样服务器传输的数据量就会大大减少了,整个网页也会被更快地显示出来。
现在,我们大部分人的浏览器都设置了缓存。所以,有时候,你会发现,即使网络没有接通,你访问的网站似乎也能“正常”打开,只不过浏览器会显示“脱机”状态,告诉你,这些内容不是真正从服务器传输过来的。
除了客户端(浏览器)能够存放缓存的内容外,代理服务器(Proxy)也能够存放网页缓存,目的同样是为了提速。你可以把代理服务器的缓存想象成CPU的“二级缓存”——当客户端没有存储某个网页的缓存的时候(“一级缓存”没有内容),浏览器就会寻找代理服务器缓存,看看有没有内容。如果还没有,那才会再去寻找真正存放网页内容的网站服务器。
有了缓存,当你点击浏览器的“回退按钮”的时候,回退的上一个页面就不需要再重新从服务器中下载一次,而是立即就呈现在你的面前。你常用的网站的打开速度也显著提升了。
可是,对于通过服务器日志来获取网站访问数据的方法而言,这可不是一个好事情。由于缓存的存在,本来应该请求服务器的结果不需要请求了,服务器的日志什么也不会记录下来,可是对页面的访问却又实实在在的发生了。
所以,缓存的存在会使日志方法低估网站的实际访问量。
2. 害怕Flash等“客户端交互”内容
现在,为了更具冲击力的视觉效果和更丰富的网页互动,运用Flash、加入视频、设计很多互动程序在网页上已经稀疏平常。而这些元素,它们太独立了,以至于当它们被载入到浏览器端了之后,完全可以在浏览器端运行而不再与服务器发生交互,或者只需要在必要的时候才与服务器发生交互。
比如,你玩儿普通网页版的Flash小游戏,一旦游戏下载完毕,你在玩儿的过程中跟网站服务器就不会有什么联系了,或者你看网页上的视频,你在播放器上进行的暂停操作,一般也不会跟服务器进行互动。还有,有一些脚本语言编写的网页程序,是在浏览器上被解释执行的,比如用JavaScript实现的网页Tab标签切换,在页面全部载完后,无论你怎么切换Tab,服务器都感觉不到了。
服务器感觉不到,也就不会存在什么服务器日志记录,也就不会有数据,因此用日志方法是无法准确获取“客户端交互”类型的网站访问行为的。这种情况下,必须选择其他的数据收集方法。
3. 不精确的访问者记录
日志方法辨别独立访问者需要依靠客户端的IP地址,也只能依靠它。不过,IP地址显然不代表真正的访问者。上班族的整个办公室的IP地址都可能是一个(使用代理服务器),而这个办公室可能坐着十多个人。这可能使访问者的数量被低估。
同样,在家中,如果你购买了公共网络服务,那么你的IP地址存在动态分配的问题。你今天上网的IP地址和明天的可能就会不同,这个时候日志方法只能判断为两个不同的访问者。这又可能使访问者的数量被高估。
此外,前面提到过日志是能够忠实记录机器(非人为)的访问活动的,但是机器不是人,它们的活动混在真实的人的访问之中,同样会使真实访问者的数量,或者访问数本身被高估。
在这正反两相反方向的共同作用下,结果只能一个,那就是对于访问者数量的估算是非常模糊的。当然,我们必须要承认,无论用什么方法,网站访问者的精确数量都无法获得,但相对而言,日志方法要更不准确些。
4. 较弱的实时性
没错,网站服务器日志是记录服务器运行的实时数据的,但是这些数据想要被取出分析,实时性就没有那么好了。常见的情况是,你必须首先把服务器日志文件(log file)从服务器中取出来,而这些文件肯定不会是服务器正在运行过程中的数据,一般都是隔天的(需要验证),然后再把这些日志文件导入到专门针对日志分析的工具中才能进行分析。这个过程的快慢依赖于你的熟练程度,但要追求实时,颇有难度。
有技术高超的站长或者工程师通过架设内部网络、组建专门的日志分析服务器,并且编写特定的程序来解决日志分析的实时性问题(http://www.phparticle.net/htmldata/36462/1/),但是,对于普通的中小网站,这种方法难度颇大,花费不菲,所以可行性不强。因此,实时性是绝大部分通过日志方法来分析网站数据时要面对的问题。
5. 海量的数据存储
 服务器日志是忠实的,所以它会如实记录下来每一分每一秒发生的每一条服务器响应。对于一些流量稍大的网站,一天的网站日志记录超过数个G(Gigabytes)是非常正常的,而那些最大的网站,一个小时就可能产生数G的记录。我们没有詹姆斯·卡梅隆的超级团队(他的《阿凡达》特效需要处理超过500,000G的数据),所以如果要回溯网站一个月的流量就可能变成一个相当棘手的问题,需要投入相当的时间和耐心,如果你没有相当的技术和经验,效率就会很低。
服务器日志是忠实的,所以它会如实记录下来每一分每一秒发生的每一条服务器响应。对于一些流量稍大的网站,一天的网站日志记录超过数个G(Gigabytes)是非常正常的,而那些最大的网站,一个小时就可能产生数G的记录。我们没有詹姆斯·卡梅隆的超级团队(他的《阿凡达》特效需要处理超过500,000G的数据),所以如果要回溯网站一个月的流量就可能变成一个相当棘手的问题,需要投入相当的时间和耐心,如果你没有相当的技术和经验,效率就会很低。
6. 日志文件获取繁琐
我们不能把日志文件的获取想象的太简单,毕竟这不是在自己卧室的电脑中点开一个MP3文件那么容易。有些网站有镜像服务器,有些服务器在境外,有些服务器是由处在多个不同地理位置的物理服务器逻辑组合而成。这些情况下,在进行日志分析之前需要集中所有的日志文件,这是一个很有些麻烦的事情,尤其是当日志文件的体积极为庞大的时候。另外,如果是租用的ISP服务器空间,如果没有权限获取日志数据,那么实际上连进行分析的可能性都没有了。
现在,你完全了解了日志方法收集网站分析数据的优缺点,那么,什么情况下你应该选择这种方法进行网站分析呢?
4. 什么情况下该用日志分析方法
如果你有如下的数据监测和分析的需要,你应该用日志分析方法:
1. 需要了解搜索引擎机器人或者其他非人为访问流量,并且希望据此对网站进行针对性的优化,如通过分析搜索引擎的访问行为来进行SEO;
2. 需要了解除了普通的PC客户端之外的上网设备对网站的访问情况;
3. 需要了解网站的文件资源是否被用户完整的下载索取;
4. 对网站流量信息具有极高的保密需要,不允许让任何第三方染指或帮忙;
5. 对于网站服务器的安全性和可维护性有要求,以及有非常显著的反抗黑客或其他非授权访问需求的。
如果有如下需求,你不应该用日志分析方法:
1. 你的网站有重要的Flash之类的“非网页类型的互动”,用户和这些内容的互动是你想要了解的内容;
2. 不喜欢麻烦,对大数据量文件的处理不擅长,对日志文件不熟悉,没有好的日志数据处理软硬件资源;
3. 需要更精确的了解网站被真正的人访问的情况,而不需要了解“非人”的机器对网站的访问并且不希望受到网页缓存的干扰;
4. 需要更好的实时性、更规律更直观的数据呈现。
现在,拿着这个清单,你可以做出容易的选择了。因为我的博客(http://www.chinawebanalytics.cn)的流量很多来自搜索引擎,因此分析服务器日志并了解搜索引擎爬虫的工作其实是非常必要的一个分析工作之一。
就我的经验而言,我们国家使用日志来分析网站仍然占有相当的比例,尤其是对于一些大型网站,他们会开发专门的软件,划拨专门的硬件资源来分析网站日志。不过,这不仅仅是从分析访问者行为的角度来考虑,更是从网站服务器的安全性和可维护性角度来考虑的。
不过,如果你把网站分析的重心放在对于网站真实访问者行为的追踪和分析上,那么,通过日志方法来实现相对而言难度相对比较大,操作也比较繁琐,我们可以利用另一种方法,即页面标记法(Page Tag)来实现对网站访问数据的收集。
好了,介绍完了,希望大家觉得看完后还算愉快!现在是大家的时间了,请您留言,任何问题,想法,不确切之处,都非常欢迎!谢谢!
